Censio AI
An assessment platform that enables concurrent evaluation of prompt versions across multiple LLMs. Create synthetic data with templates, generate ground truth using powerful LLMs, run prompts, and review against ground truth with comprehensive quality metrics including hallucination detection, conciseness, relevance scoring, and deep-layer interpretability.
Platform Interace
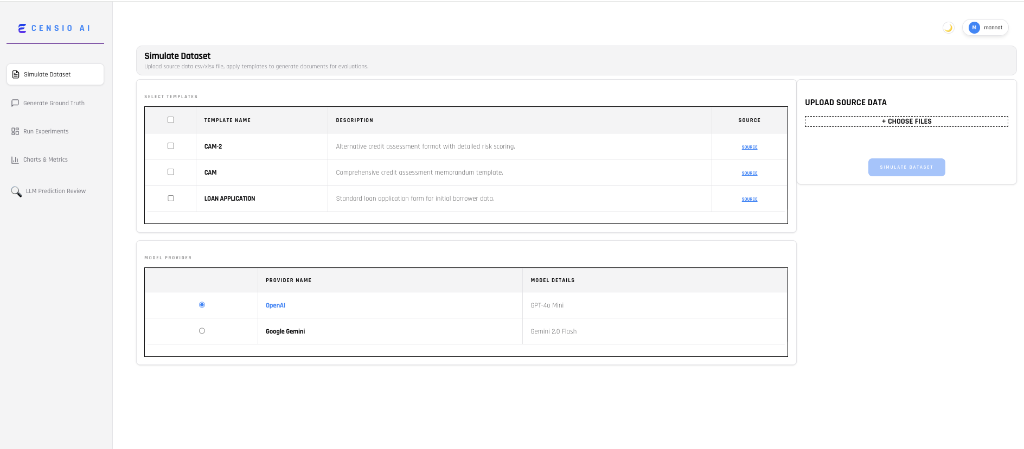
Simulate Dataset & Source Data
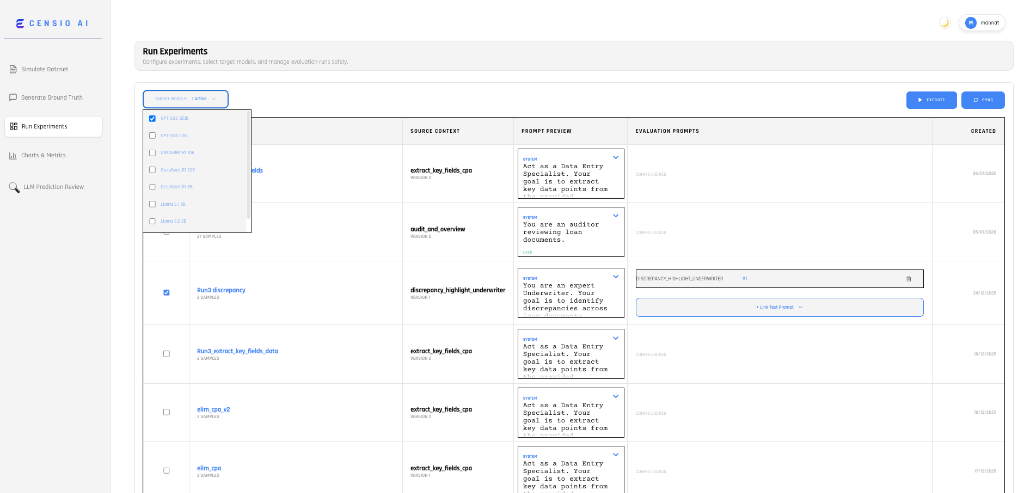
Run Experiments Configuration
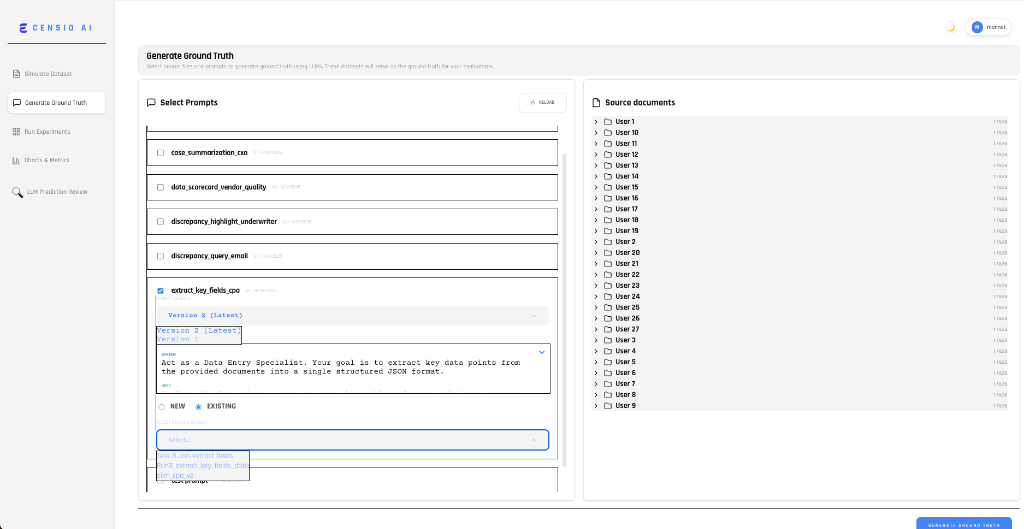
Generate Ground Truth
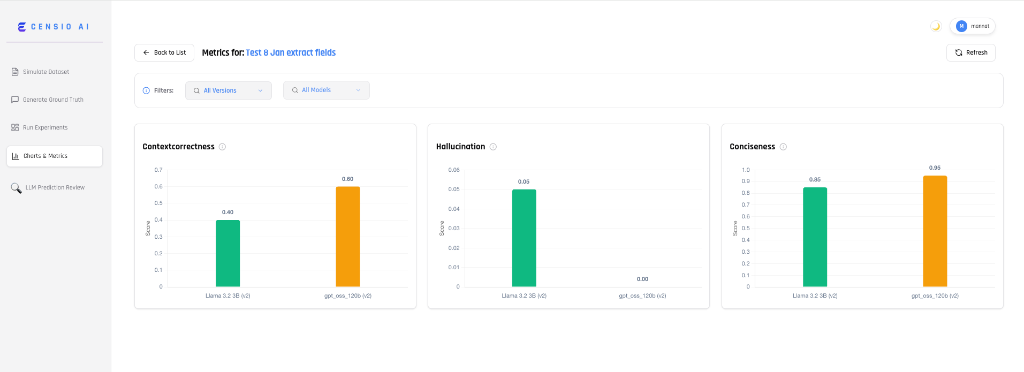
Quality Metrics Dashboard
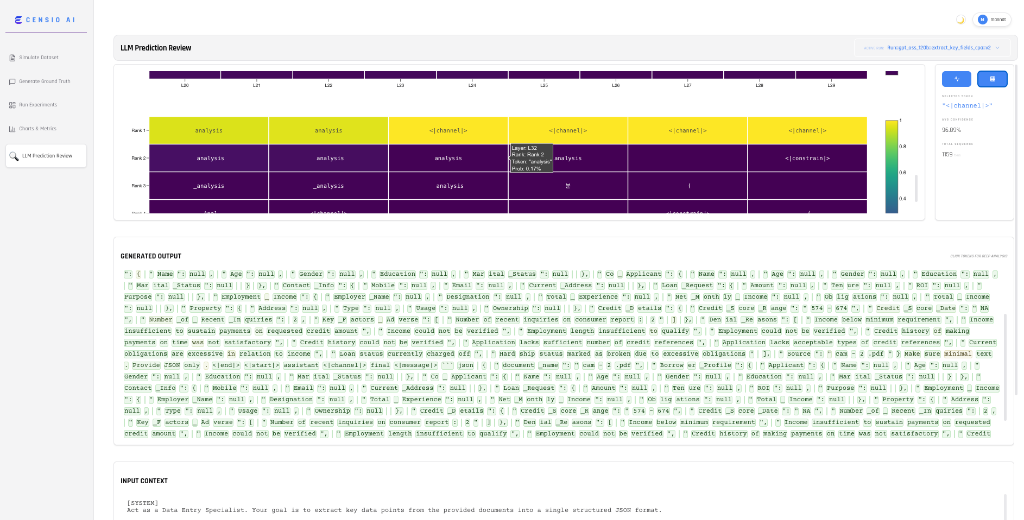
Deep-Layer Interpretability Review
Salient Features & Capabilities
Concurrent Multi-LLM Benchmarking
Eliminate the "one-by-one" bottleneck. Test different prompt versions across multiple LLMs (e.g., GPT-OS 120B, Llama 3B & others) simultaneously to see exactly how each model handles your specific use case in real-time. We can support you to run your models as well.
Template-Driven Synthetic Data Generation
Scale your testing instantly. Use customizable templates to generate thousands of diverse synthetic data points, ensuring your model is battle-tested against a wide range of edge cases without the manual effort.
Automated Ground Truth Creation
Establish a "Gold Standard" effortlessly. Utilize powerful teacher models to generate high-quality ground truth responses, providing a reliable baseline for measuring the performance of your target LLMs.
Comprehensive Quality Metrics
Get a 360-degree view of model performance with automated scoring for:
- Hallucination Detection: Pinpoint factually incorrect or ungrounded outputs.
- Conciseness: Ensure your model is efficient and avoids "word salad."
- Relevance: Verify that the AI actually answers the user's intent.
Deep-Layer Interpretability (The "X-Ray" View)
Go beyond the final text output. Censio's X-Ray feature provides a transparent view into the model's "brain" by visualizing token predictions and confidence scores across internal transformer layers. Analyze how the model's reasoning evolves layer-by-layer to pinpoint exactly where hallucinations begin, detect semantic drift, and understand the root cause of errors before they reach the final output.
Closed-Loop Prompt Engineering
Rapidly iterate on your prompts based on quantitative scores. Compare the delta between versions to see exactly which tweaks improved your relevance or reduced your hallucinations.